





 8445
8445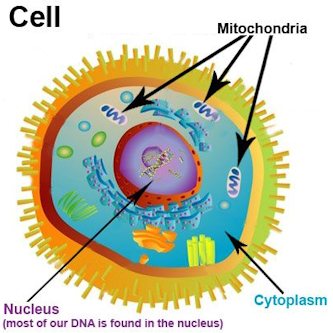
Je n’ai pas été personnellement exposé à cette maladie, mais son incidence (croissante ?) chez des personnes de tous âges m’a incité à collecter des informations sur son traitement.
Il est encourageant de savoir que la recherche s’oriente vers une prévention plus efficace de cette maladie, des techniques de dépistage fiables, et la mise en œuvre de traitements ciblés, moins agressifs.
La lecture des publications scientifiques, et encore plus celle de communiqués de presse annonçant des avancées exceptionnelles — nécessite une grande prudence dans la mesure où cet espace de communication est la cible idéale d’articles frauduleux. Cette tendance est devenue encore plus forte avec l’apparition de dizaines de paper mills : de fausses revues publiant de faux articles (ou la contrefaçon de vrais articles) sous le couvert de comités éditoriaux fictifs dont les membres affichés ne connaissent pas l’existence. Lire à ce sujet les nombreux articles dans la catégorie cancer research du site For Better ScienceN1.
Sommaire
⇪ Facteurs de risque et causes du cancer
Dans mon article Vivre longtemps, j’ai attribué la baisse de l’espérance de vie en bonne santéN2 à une exposition à des risques classés dans deux catégories : environnementaux et comportementaux. On peut utiliser ces catégories pour classer les facteurs de risque d’incidence du cancer. Les facteurs environnementaux sont ceux sur lesquels nous ne pouvons agir que collectivement : pollution, utilisation de produits phytosanitaires, substances radioactives, molécules cancérigènes présentes dans les textiles, cosmétiques et autres produits industriels etc., sans oublier l’exposition accidentelle à certaines maladies infectieuses. Les facteurs comportementaux comprennent la nutrition, l’activité physique, le stress, la consommation abusive d’alcool, de sucre, de sel, de tabac et de stupéfiants, l’exposition excessive au soleil, la quantité et la qualité du sommeil etc., sur lesquels il est possible d’intervenir individuellement dans la limite des contraintes économiques et sociales. Les conclusions d’un groupe de travail (Lauby-Secretan B et al., 2016N3) révèlent que 9% des cancers chez les femmes en Amérique du Nord, en Europe et au Proche-Orient seraient liés à l’obésité.
Il est capital de ne pas faire d’amalgame entre « facteurs de risque » et « causes ». Les premiers sont l’interprétation d’une corrélation qui ne suffit pas à établir une causalité. À titre d’exemple, les graphiques ci-dessous affichent des corrélations supposées « prouver » qu’une cause de l’autisme serait le très controversé glyphosate (herbicide Roundup™ N4) ou… la vente d’aliments bio ! 😉
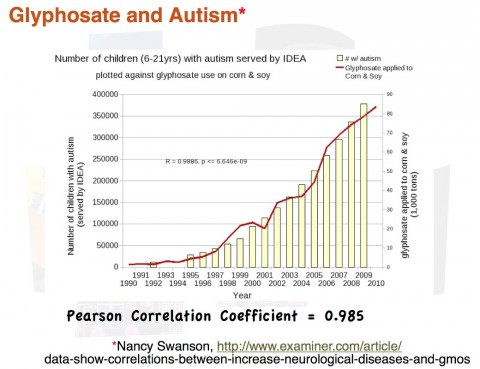
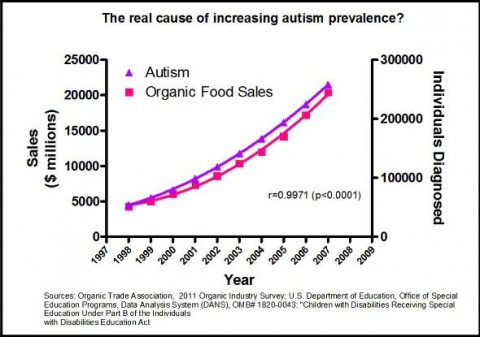
abusivement pour « prouver » un lien de causalité entre des phénomènes
choisis arbitrairement.
Une analyse statistique bien conduite permet d’isoler un facteur de risque en neutralisant au mieux les effets des variables parasitesN5 mais il ne faut pas confondre ce procédé de calcul avec la découverte d’une cause ; la corrélation n’est jamais qu’un indice dans la recherche des coupables. L’accès de plus en plus généralisé à des données statistiques donne lieu à toutes sortes de théories déviantes — parfois même manipulatrices — comme l’illustrent de manière humoristique des appariements insolites de graphes (voir exemplesN6). Il a fallu par exemple plusieurs décennies pour prouver que fumer était bien une cause de cancer du poumon, alors que le facteur de risque était connu, les industriels du tabac ayant tout fait pour retarder la constitution de cette preuve (Lagrue, 2009N7).
Certains médias sont prompts à ériger le risque de cancer comme un épouvantail pour induire des changements de pratique en mettant en exergue un seul facteur de risque. Aujourd’hui, les pratiques nutritionnelles sont mises à l’index dans une rhétorique qui paraît relever du bon sens mais s’appuie sur une lecture biaisée d’études épidémiologiques — voir mon article Faut-il jeter les enquêtes nutritionnelles ?
Par exemple, selon l’enquête NutriNet-Santé (Fiolet T. et al, 2018N8) portant sur des Français d’âge moyen 42.8 ans, l’incidence des cancers du sein, de la prostate ou colorectal augmenterait de 12% chez les sujets dont 10% de la nourriture est composée d’aliments « fortement transformés ». Il s’agit toutefois d’une augmentation de risque relatif : l’incidence moyenne étant d’environ 0.5% sur 5 ans, l’augmentation de risque absolu était de 0.1%. L’étude ayant dénombré 2228 cancers dans la période de suivi, cette augmentation se réduisait à 2 cas… De plus, comme le suggère Gid M‑K (2018N9), pour modifier défavorablement l’origine de 10% de sa nourriture il faut vraiment beaucoup fréquenter les fast-foods…
À l’inverse, selon des sources médiatiques, manger « bio » réduirait le risque de cancer… Les biais méthodologiques de l’étude observationnelleN10 citée à l’appui de ce message publicitaire sont exposés dans l’article Consommation d'aliments bio et risque de cancer. Une consommation régulière de viandes transformées (2 tranches de bacon par jour) augmenterait de 18% le risque de cancer colorectal (risque relatif). Cette augmentation pourrait être liée à l’addition de nitritesN11 dont l’association avec les protéines et l’hèmeN12 produirait des nitrosaminesN13 cancérigènes lors de la cuisson à haute température. Mais cette observation mérite aussi d’être tempéréeN14 sachant par ailleurs que l’augmentation de risque reste marginale en comparaison avec la consommation de tabac qui augmente le risque de 2500%N15 — voir mon article Protéines.
➡ Ne pas en conclure que la consommation quotidienne de nourriture industrielle n’aurait aucun effet délétère sur la santé. On voit seulement que l’effet à court terme sur un risque de cancer était négligeable pour la population étudiée.
Les causes des cancers, en réalité, apparaissent multifactorielles, autant par la diversité des interactions du patient avec son environnement que par celle des mécanismes en jeu dans son évolution. Une maladie est dite multifactorielle quand son apparition renvoie à divers facteurs génétiques et environnementaux. C’est le cas de la plupart des pathologies courantes, associant dans leur étiologie le terrain héréditaire et l’histoire de vie du patient (INSERM).
Comme le résume Janlou Chaput (2012N16) :
La biologie cellulaire est très complexe : il s’agit de jeux d’équilibres, de rétrocontrôles, d’inhibitions, de transformations, etc. Chaque cas de cancer est particulier et fait intervenir différents acteurs qui ne sont pas impliqués dans toutes les formes.
⇪ L’effet Warburg

Bundesarchiv, Bild 102–12525 /
Georg Pahl / CC-BY-SA 3.0
La découverte de mécanismes génétiques à l’œuvre dans l’évolution du cancer (voir plus bas) a longtemps éclipsé celle d’Otto Heinrich WarburgN17, chercheur en biologie qui avait reçu en 1931 le Prix Nobel de médecine pour sa découverte sur le métabolisme des cellules de tumeurs cancéreuses (effet WarburgN18).
Rappelons, pour commencer, que les mitochondriesN19 sont des organitesN20 similaires à des bactéries (mais sans noyau) que l’on trouve dans le cytoplasmeN21 de toutes les cellules du corps, à l’exception des cellules sanguines. Leur nombre dans une même cellule peut varier d’une dizaine à plusieurs milliers. Elles possèdent leur propre ADN, beaucoup plus simple que celui du noyau cellulaire et hérité exclusivement de la mère. L’ADN que l’on peut séquencer dans des fossiles humains est seulement de l’ADN mitochondrial.
Les mitochondriesN19 sont connues principalement pour leur rôle de « centrales d’énergie » des cellules, utilisant comme ressources (dans les cellules saines) aussi bien les réserves de sucre que de graisse. Ce « choix du carburant » est probablement le résultat d’un processus évolutif, les humains ayant dû s’adapter à des environnements où les ressources nutritives venaient périodiquement à manquer. Il s’ensuit que les pratiques nutritionnelles des ethnies ont favorisé, selon leur lieu d’habitat, tantôt des régimes riches en glucides et tantôt en lipides.
Les mitochondriesN19 interviennent aussi dans l’apoptoseN23 : la mort cellulaire programmée des cellules dont l’ADN a été endommagé. Lorsque le mécanisme d’apoptose est perturbé, des amas de cellules défectueuses peuvent s’accumuler en répliquant le code modifié. On assiste à la formation d’une tumeur — qui n’est pas forcément cancéreuse. Une tumeur cancéreuse devient « maligne », et particulièrement dangereuse, quand des cellules s’en détachent pour coloniser d’autres endroits du corps : c’est le processus de métastaseN24 qui rend beaucoup plus incertaine la guérison par ablation chirurgicale de la tumeur.
Les cellules cancéreuses, comme beaucoup de celles qu’on cultive in vitro, fabriquent leur énergie principalement à partir du glucose, par un mécanisme d’assimilation (glycolyseN25) suivi de fermentation produisant de l’acide lactiqueN26 dans le cytoplasmeN21 de la cellule, plutôt que de faire appel, comme les cellules saines, à un mécanisme plus complexe : une glycolyse moins intense suivie d’une oxydation du pyruvateN27 à l’intérieur des mitochondriesN19, qu’on appelle cycle de KrebsN28.
Ces mécanismes sont très compliqués à décrypter mais il n’est pas nécessaire de les comprendre pour lire la suite ! 🙂 Toutefois, attribuer exclusivement à l’effet Warburg les dysfonctionnements qui conduisent à la formation et la prolifération de cellules cancéreuses est un raccourci intellectuel qui fait le bonheur de marchands de thérapies « alternatives », mais ne reflète qu’une partie de la réalité. Les mécanismes sont bien plus variés et complexes car les cellules tumorales savent mettre en place d’autres voies pour la production d’énergie. Une analyse plus proche des données scientifique est exposée dans mon article Cancer - approche métabolique et Cordier-Bussat, M. et al. (2018N29).
Le métabolisme de production d’énergie à partir du glucose, dans les cellules cancéreuses, pourrait découler d’une altération des mitochondriesN19 associée au cancer, de l’adaptation des cellules tumorales à un environnement faible en oxygène, ou encore des oncogènesN30 empêchant les mitochondries de mener à bien la destruction des cellules cancéreuses (apoptoseN23). Les oncogènes sont des gènes qui, une fois activés, provoquent la croissance et la prolifération des cellules. Le métabolisme perturbé pourrait aussi être un effet de la prolifération cellulaire (voir discussionN18).
Le rôle des mitochondriesN19 n’était pas encore bien connu à l’époque de Warburg, mais il avait bien identifié, sans pouvoir les expliquer, les mécanismes fondamentaux : au lieu de respirer normalement en présence suffisante d’oxygène, les cellules cancéreuses fermentent. Elles fabriquent pour cela d’importantes quantités d’acide lactique. Cette découverte a donné lieu à l’hypothèse de WarburgN31 selon laquelle le cancer serait causé par une diminution de la respiration mitochondriale qui obligerait les cellules à recourir à un processus archaïque (d’un point de vue évolutionniste) de fabrication d’énergie à partir du seul glucose. Cette formulation simple de l’hypothèse — qui ne correspond pas à certains cancers comme celui de la prostate — est suffisante pour la compréhension de ce qui suit. Je recommande l’audition de l’excellente émission La méthode scientifique du 24/6/2019 : Mitochondrie, de l’énergie plein la celluleN32 pour une explication plus détaillée.
Il est reconnu aujourd’hui qu’un dérèglement du métabolisme contribue à la croissance et la prolifération de cellules cancéreuses (oncogenèseN33). La question qui donne lieu à controverse est de savoir si ce dérèglement est (toujours ?) une cause première du cancer. Les chercheurs Hirschey MD et al. (2015N34) déclarent :
Alors que plusieurs preuves convaincantes suggèrent que la reconfiguration métabolique est causée par l’action concertée des oncogènesN30 et des gènes suppresseurs de tumeurs, en certaines circonstances le métabolismeN35 peut jouer un rôle primaire dans l’oncogenèseN33. Récemment, des mutations des enzymesN36 cytosoliquesN37 et mitochondriales impliquées dans les voies métaboliques principales ont été associées à des formes héréditaires et sporadiques de cancer. Dans l’ensemble, ces résultats montrent que le métabolisme aberrant, une fois vu comme un épiphénomèneN38 de la reprogrammation oncogénique, joue un rôle clé dans l’oncogenèse, avec le pouvoir de contrôler aussi bien les événements génétiques qu’épigénétiquesN39 dans les cellules.
La liste des co-auteurs de cet article comprend quelques noms à retenir, entre autres Ko, Longo et Pedersen dont il sera question plus bas.
⇪ Explication génétique

Selon la théorie « génétique » dominante aujourd’hui (Somatic Mutation Theory, SMT), l’effet Warburg N18 ne serait pas la cause du cancer mais un processus d’adaptation consécutif à des mutations qui ont déclenché la croissance et la prolifération des cellules.
En 1989, J. Michael Bishop et Harold E. Varmus ont reçu le Prix Nobel pour leur découverte de l’origine cellulaire des oncogènes rétroviraux. En 1916, Peyton Rous, un autre lauréat du Prix Nobel de médecine, avait découvert un virus oncogèneN40 dans la vaste famille des rétrovirus porteurs d’un matériel génétique appelé ARN (acide ribonucléiqueN41). Cet ARN peut être transcrit en ADN par une enzyme spécifique de ce virus (transcriptase inverseN42). La transcription inverse a pour effet que le matériel génétique du virus peut être intégré à l’ADN de la cellule hôte. Bishop et Varmus ont découvert que l’oncogèneN30 dans le virus de Rous n’était pas un véritable gène de virus, mais qu’il avait été prélevé de la cellule pendant la reproduction du virus, et qu’il contrôlait la taille et la division des cellules. Par la suite, plus de 40 oncogènes différents ont été identifiés. La modification d’un ou plusieurs oncogènes peut se traduire par le cancer.
Toute détérioration d’un organe donne lieu à des processus réparateurs complexes au cours desquels une cellule peut échapper au processus de contrôle de la croissance, et donc déclencher une prolifération anormale de cellules, dans le pire des cas un cancer. Le processus du cancer implique plusieurs changements consécutifs du matériel génétique — on ne sait pas a priori combien. L’étude des gènes cellulaires (proto-oncogènes) commence à clarifier les mécanismes compliqués gouvernant la croissance et la division des cellules.
Sans entrer dans les détails (voir le communiqué de presseN43), les découvertes qui ont suivi celle de Bishop et Varmus ont abouti à une description du cancer comme une maladie causée par des mutations génétiques. Il peut s’agir de modifications de gènes hérités des parents, dans environ 5% à 10% des cas, qui prédisposent au cancer mais ne suffisent pas à le déclencher. Le plus souvent, ces mutations interviennent pendant la vie du patient, par exemple suite à son exposition au soleil ou aux effets de susbstances cancérigènes ; dans ce cas, seules les cellules cancéreuses sont porteuses de la mutation.
Au moment de la division cellulaire, si l’ADN n’a pas été copié correctement, une cellule saine est sujette à un mécanisme d’apoptose (N23 mort cellulaire programmée). Mais si ce mécanisme a été inhibé en raison d’un silence des gènes suppresseurs de tumeursN44, les cellules se mettent à proliférer en propageant du matériel génétique incorrect.
Laurent Schwartz, qui poursuit des pistes complémentaires de traitement du cancer comme une maladie métabolique (voir mon article), souligne les limites de cette explication. Il justifie ainsi son approche (2019N45, page 58) :
Aujourd’hui, il est admis que rares sont les cancers à avoir une explication strictement génétique. Si une anomalie héréditaire peut expliquer la survenue de certains cancers de l’enfant ou du jeune adulte, le facteur génétique n’explique pas les cancers les plus fréquents — j’entends ceux de l’homme mûr ou du vieillard. La piste génétique s’est donc révélée erronée. Le génome n’est qu’une des pièces du puzzle que nous devons tenter de dévoiler.
Cette critique a été présentée de manière très compréhensible par Eléonore Djikeussi dans son ouvrage Cancer : maladie génétique ou crise énergétique cellulaire ? (2022N46 p. 54–57). Elle écrit :
Les promesses étaient immenses. En effet, le Projet du Génome Humain [N47] a permis d’identifier les anomalies génétiques présentes dans les cellules au cours des différentes maladies. Mais, s’agissant du cancer, il n’a pas été e mesure de déterminer le rôle causal de celles-ci, pas plus que n’y avaient réussi Theodor Boveri et David Hansemann en leur temps au tout début du XXe siècle.
Il a stimulé depuis 40 ans un engouement frénétique pour le gène, « le langage par lequel Dieu a créé la vie », et orienté avec une vision myope la recherche sur le cancer.
[…]
Ce projet a cependant permis d’établir le fait que les cancers comportent une hétérogénéité génétique y compris au niveau de la même famille de tumeurs, que des mutations apparaissent au cours de l’évolution d’un cancer, surtout après des thérapies chimiques comportant notamment des molécules telles que les alkylants [N48], et après des traitements tels que la radiothérapie. Le PGH a ainsi permis de confirmer qu’il n’existe pas un gène du cancer (à ce jour).
⇪ Cellules souches
Tomasetti C et Vogelstein B (2014N49) ont observé que la capacité pour un tissu de produire des cellules cancéreuses tenait au nombre de divisions des cellules souchesN50. Ils ont observé une très forte corrélation entre les taux d’incidence de divers cancers et une estimation du nombre normal de divisions des cellules souches dans ces tissus. Cette corrélation suggère, selon eux, qu’un des principaux facteurs du développement du cancer serait les erreurs se produisant de manière aléatoire dans la copie de l’ADN des cellules souches normales. Ce « pas de chance » expliquerait, selon eux, l’apparition des cancers bien plus fréquemment que les facteurs environnementaux et héréditaires, soit 2/3 des cas pour 22 types de cancers qu’ils ont étudiés (voir pageN51). Les cancers du sein et de la prostate n’étaient toutefois pas inclus dans leur étude.
Il a été reproché à ces chercheurs de confondre corrélation statistique et relation causale. Annie Thébaud-Mony écrivait dans Le Monde (07/01/2015N52) :
Pour eux, sans aucun doute, cette « découverte scientifique » devrait clore toute controverse sur le rôle des risques industriels dans la survenue du cancer !
Elle ajoute que la cellule souche ne se transforme pas spontanément en cellule cancéreuse. Elle le fait sous l’effet de mutations qui elles-mêmes sont produites par des agents cancérogènes externes. La simple corrélation observée ne rend pas compte des très fortes disparités d’origine sociale face au risque de cancer, qui est en France dix fois plus élevé chez les ouvriers ou employés que chez les cadres supérieurs. Annie Thébaud-Mony signale enfin un troisième angle mort de la démonstration de Tomasetti et Vogelstein, au-delà des études purement épidémiologiques :
Cette maladie commence, certes, au cœur des cellules mais s’inscrit, pour chaque individu touché, à la croisée de deux histoires. L’une est celle des atteintes, simultanées et/ou répétées, provoquées par les agents toxiques (poussières, substances chimiques, rayonnements) au cours de multiples événements de la vie professionnelle, résidentielle, environnementale et comportementale ; l’autre est, face à ces agressions, celle des réactions de défense de l’organisme, elles-mêmes extrêmement variables selon les individus.
Comme précisé dans WikipediaN53, certains cancers induits par certains comportements transmis de génération en génération (consommation d’alcool ou de tabac) peuvent être confondus avec un risque génétique vrai, et inversement certains gènes prédisposant au cancer pourraient n’être activés que dans certaines circonstances (obésité, alcoolisme, etc.).
La complexité et la variabilité des mécanismes de mutation pourraient faire dire que — si l’on s’en tient à la description génétique de la maladie — il y aurait autant de formes de cancer que de malades. David Gorski (2011N54) écrit :
Non seulement le cancer n’est pas une maladie unique, mais les cancers individuels sont constitués de clones multiples de cellules cancéreuses soumises à une pression sélective qui les rend encore plus invasives et mortelles. Vu sous cet angle, on se demande pourquoi nous ne mourons pas tous de cancer. Nous avons tous, certes, virtuellement des petits foyers de cancer en nousN55, comme je l’ai déjà signalé. Toutefois, la plupart d’entre nous ne développent pas un cancer, et encore moins finissent par mourir de cancer, bien que le cancer soit en train de rattraper les maladies de cœur comme cause première de décès dans les sociétés industrielles. Heureusement, les étapes nécessaires au cancer pour devenir mortel sont difficiles et nombreuses, et les défenses du corps contre le cancer sont formidables.
À l’appui de cette proposition, le fait que le cancer existait bien avant l’époque industrielle qui a produit en quantité des substances cancérigènes, voire même à l’époque préhistorique selon les découvertes récentes sur des fossiles (voir articleN56).
⇪ De la génomique à la protéomique
L’avènement de techniques de séquençage d’ADNN57 a permis de lancer aux USA, en 2005, The Cancer Genome Atlas (TCGA, « L’atlas du génome du cancer »N58) visant à identifier les schémas de mutations associées à toutes les formes de cancer.

Source : N59
Jean Claude Zenklusen annonce le 8 février 2016 (voir pageN59) :
Après avoir collecté des échantillons de plus de 11000 patients couvrant 33 types de tumeurs, et créé une base de données vaste et compréhensible pour la description des changements moléculaires qui se produisent dans les cancers, le projet The Cancer Genome Atlas est en train de s’achever. La collecte des échantillons de tissus et la génération des données sont terminées. Dix-huit analyses intégratives de types de cancers individuels ont été publiées et les analyses de quinze autre articles sont en cours.
Dans le même communiqué, le directeur de TCGA reconnaît que l’utilisation de ces données aux fins d’applications cliniques est encore au stade préliminaire. Il ajoute : « Dans le projet Exceptional Responders, plusieurs des tumeurs analysées jusqu’ici révèlent une explication génomique évidente de la réponse exceptionnelle au traitement. »
L’investissement financier dans ce projet serait aux alentours de 575 millions de dollars (sourceN60).
L’oncologue David Agus débute sa conférence TEDmed en 2009N61 par le constat que, depuis 1950, on n’a pas réussi à diminuer le taux de mortalité du cancer malgré la mobilisation massive de moyens financiers et humains. Il rappelle l’importance d’un diagnostic précoce qui permet de traiter le cancer avec une meilleure estimation de durée de survie, et affirme que l’investissement principal devrait être dans la prévention — ce que la suite de son exposé ne fait que contredire… Il déplore une tendance « réductionniste » qui consiste à rechercher l’explication du cancer dans l’activation d’un petit nombre de gènes. (Le projet The Cancer Genome Atlas en était à son début, mais les analyses statistiques avaient déjà montré que les données étaient moins parlantes qu’on l’aurait espéré.)

Source : N62
Selon Agus, le vocabulaire descriptif du cancer est pauvre et archaïque : une maladie diagnostiquée uniquement par ses symptômes ou sa localisation dans le corps ne peut pas donner lieu à une thérapie basée sur des règles. Un symptôme n’est que la manifestation de dérèglements. Agus espère qu’une approche technologique sur le modèle de TCGA fera émerger une nouvelle base descriptive basée sur la génétique : « Une rupture assurée par la technologie dans la pratique du soin sera celle qui permet un diagnostic précis du cancer par sa cause plutôt que par la localisation anatomique ou des symptômes physiques ». En d’autres termes, passer de l’art de la médecine à la science de la médecine, comme on l’a fait pour les maladies infectieuses grâce à l’identification de bactéries ou de virus.
Le cancer n’est pas une maladie génétique…
Serait-ce plutôt une maladie du micro-environnement ? L’évolution sélectionne le phénotype, pas le génotype. Or le cancer est l’interaction d’une cellule avec son environnement.
Le but n’est donc pas de comprendre le cancer mais de le contrôler : la compréhension est un outil en vue du contrôle [???]. On s’est trompé en devenant réductionniste.
Il évoque sans transition la protéomiqueN64 et son travail avec Danny Hillis (voir vidéoN63). Cette technique nouvelle rend possible un recensement des protéomesN65, c’est-à-dire l’ensemble des protéines d’une cellule, d’un organite, d’un tissu, d’un organe ou d’un organisme à un moment donné et sous des conditions données. L’électrophorèse bidimensionnelle N66 permet, à partir de mélanges protéiques complexes, de séparer et visualiser des centaines voire des milliers de protéines sous forme de taches ou « spots » (WikipediaN64).
L’analyse protéomique est une étude dynamique, dans laquelle la dimension du temps peut être prise en compte, alors que l’analyse génomique ne rend compte que d’un état. Un seul génome peut conduire à différents protéomes en fonction des étapes du cycle cellulaire, de la différenciation, de la réponse à différents signaux biologiques ou physiques, de l’état physiopathologique… Le protéome reflète les répercussions de ces événements cellulaires au niveau tant traductionnel que post-traductionnel. De ce point de vue, seule une analyse protéique directe peut donner une image globale des systèmes biomoléculaires dans leur complexité (WikipediaN64). Les études comparées des kinomesN67 de cellules cancéreuses devraient permettre d’étudier des mécanismes de résistance et d’identifier de nouvelles cibles thérapeutiques.
En contradiction avec cette nouvelle perspective techno-scientifique (projet MMRF Proteomics Initiative), l’argument final d’Agus est que, plutôt que chercher à « comprendre » la maladie, il conviendrait d’analyser pourquoi certaines thérapies médicamenteuses ont réussi dans certains cas. Il donne un exemple d’administration empirique d’un médicament (acide zolédroniqueN68) en complément de la chimiothérapie à un groupe de femmes souffrant de cancer du sein, qui a abouti sur deux ans à une diminution de 36% de la mortalité, alors que ce médicament n’avait aucun effet sur les cellules cancéreuses. Il ajoute qu’aucune « chimio » connue à ce jour n’agit directement sur la cellule cancéreuse, faisant l’éloge d’une approche thérapeutique par essai et erreur qui sera peut-être améliorée — mais on ne voit pas bien comment — par la mise en œuvre de l’attirail technologique. Une métaphore poétique permet de rassurer les spectateurs : « On a réduit le cancer avec un médicament qui ne touchait pas au cancer, un peu comme modifier le terrain pour que la graine pousse différemment. »
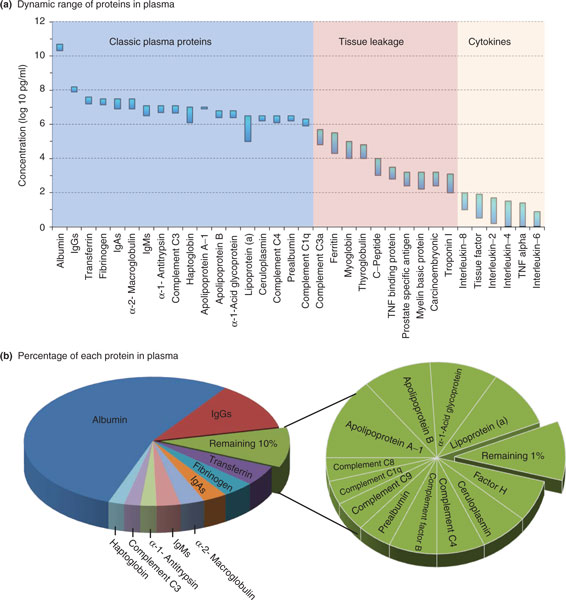
Source : N69
Il reste que cette approche par essai et erreur n’est autre que la continuation de 59 années de tâtonnements dans la lutte contre le cancer. L’optimisme affiché par Agus dans cet exposé apparaît comme une façade. Son patient et ami Steve Jobs était encore en vie à cette époque. C’est d’ailleurs lui qui l’avait convaincu de choisir une « pensée positive » comme titre de son livre : The End of Illness (« La fin de la maladie ») — voir articleN62…
La génomiqueN70 de TCGA et la protéomiqueN64 proposée par Hillis et Agus mettent en œuvre des algorithmes d’apprentissage automatique (machine learning) sur de très grandes quantités de données, une approche popularisée aujourd’hui sous l’appellation Big Data N71. Une des difficultés de l’analyse des protéines est un facteur d’échelle — le rapport entre les concentrations les plus élevées et les plus faibles est de l’ordre de 1011 (cent milliards) alors que les protéines ciblées par l’analyse (cytokinesN72) figurent au bas de l’échelle. Pour un électronicien, ce que le conférencier désigne élégamment comme un « ordre de grandeur de magnitude 11 » est analogue à un phénomène dont l’observation nécessiterait un dispositif d’amplification de rapport signal sur bruit supérieur à 110 dB !
L’article de Maryáš J et al. (2014 autre N73) fait le point sur cinq années de recherche en protéomique, citant 112 références bibliographiques. Il admet que la traduction des découvertes dans ce domaine en termes de diagnostic et d’expérimentation clinique restent inscrites dans un « avenir proche » (sic) :
Comme cela a été montré dans les études examinées ici, de nombreuses protéines ont été identifiées par les technologies de protéomiqueN64 comme clairement associés à un processus complexe de métastase du cancer, sur la base de l’analyse protéomique des tissus, des systèmes modèles, du sécrétome, ou l’analyse des protéines de surface avec une vérification quantitative et/ou fonctionnelle des résultats. La protéomique a également contribué à la description fonctionnelle de ces objectifs, que ce soit dans le cadre des études fonctionnelles, ou par l’analyse des interactomesN74. Il est donc évident que la protéomique actuelle a un potentiel pour fournir des données fonctionnellement significatives dans ce domaine. Ceci est positif car de nombreux écrans protéomiques, en particulier dans le passé, n’avaient affiché que les protéines très abondantes. Cela a été à juste titre interprété comme une preuve de l’utilité limitée de la méthodologie. En outre, il est évident que la traduction de n’importe lequel de ces résultats en essais cliniques généralement valides et en approches thérapeutiques nécessitera une validation complète sur de grandes séries d’échantillons cliniques, et deviendra une tâche longue, exigeante, pas toujours couronnée de succès.
Néanmoins, nous supposons que l’augmentation de la couverture du protéomeN65 réalisable avec les dernières technologies de protéomique non ciblées, en combinaison avec l’augmentation de la capacité d’échantillonnage de la protéomique ciblée, est capable, dans un avenir proche, de rapprocher la protéomique du cancer des applications cliniques.
Confronté aux incohérences apparentes des schémas de mutation induits par l’étude systématique des données de TCGA, Bert Vogelstein a désigné comme « matière noire »N75 les phénomènes encore non-identifiés susceptibles de restaurer cette cohérence. Ce terme avait été inventé pour désigner une catégorie de matière hypothétique, invoquée pour rendre compte d’observations astrophysiques inexplicables par d’autres moyens.
Dans Tomasetti, Cristian et al. (2015N76), Vogelstein écrit :
La rareté des mutations pourrait indiquer qu’il y a de la « matière noire » dans le génome du cancer, à savoir, des changements épigénétiquesN39 et des altérations génomiques qui ne peuvent pas être facilement identifiés par un séquençage parallèle massif ni d’autres méthodes couramment utilisées.
⇪ Épigénétique ?
L’épigénétiqueN39 désigne tout changement d’expression des gènes qui n’implique pas de changement dans la séquence ADN, qui est stable mais demeure réversible. Elle s’intéresse à une “couche” d’informations complémentaires qui définit comment ces gènes sont susceptibles d’être utilisés par une cellule.
Cette approche, qui défie (en partie) le déterminisme du « capital génétique » enfermé dans notre ADN, a suscité l’essai de nouveaux médicaments, appelés « épidrogues ». Edith Heard déclarait dans Le Monde (Rosier F, 2012N77) :
Les variations épigénétiques sont finalement assez plastiques. Elles peuvent être effacées par des traitements chimiques, ce qui ouvre d’immenses perspectives thérapeutiques. Cet espoir s’est déjà concrétisé par le développement de premières « épidrogues » pour traiter certains cancers
Les perspectives sont moins prometteuses à court terme que ne le laissent espérer les informations qui circulent dans les médias. Dans CNRS Le Journal (n°295, 2019 page 34), Edith Heard précisait :
Le problème, avec le cancer, c’est que rien n’est simple : le génome est modifié, avec des mutations de gènes, et l’épigénome est modifié aussi, sans que l’on sache si ces changements sont liés et dans quel sens ils opèrent. L’utilisation des épidrogues pose aussi des questions, car elles n’agissent pas de façon ciblée, sur un gène ou deux, mais sur l’ensemble des marques épigénétiques de l’individu, avec des conséquences que l’on ne maîtrise pas encore complètement. Voilà où on en est aujourd’hui [2019], sur le cancer et l’épigénétique. Ce sont des recherches qui suscitent beaucoup d’espoir, mais qui n’avancent pas très vite. À nouveau, cela demande de faire énormément de recherche fondamentale. Contrairement au génome, qui lui a été décrypté entièrement, on ne connaît pas encore tout sur notre épigénome, en particulier dans le domaine du cancer.
(Suite sur la page Cancer - nouvelles pistes)
➡ Les références bibliographiques complètes sont sur la page Cancer - conclusion et références.
➡ Le contenu de cet article ne se substitue pas aux recommandations des professionnels de santé consultés par les lecteurs.
▷ Liens
🔵 Notes pour la version papier :
- Les identifiants de liens permettent d’atteindre facilement les pages web auxquelles ils font référence.
- Pour visiter « 0bim », entrer dans un navigateur l’adresse « https://leti.lt/0bim ».
- On peut aussi consulter le serveur de liens https://leti.lt/liens et la liste des pages cibles https://leti.lt/liste.
- N1 · 6wom · Cancer research – Fraudulent research papers tagged on “For Better Science”
- N2 · kxnn · Espérance de vie en bonne santé – Wikipedia
- N3 · 3rsf · Lauby-Secretan, B et al. (2016). Body Fatness and Cancer — Viewpoint of the IARC Working Group.
- N4 · 52x0 · Glyphosate – Wikipedia
- N5 · 7f6i · Variable confondante – Wikipedia
- N6 · zv2e · Funny Graphs Show Correlation Between Completely Unrelated Stats
- N7 · hj8c · Lagrue, Gilbert (2009). Quand l’industrie du tabac cache la vérité scientifique. SPS n°284.
- N8 · n193 · Fiolet, T et al. (2018). Consumption of ultra-processed foods and cancer risk : results from NutriNet-Santé prospective cohort. British Medical Journal, 360:k322.
- N9 · bygg · Gid, M‑K (2018by). Processed Food Isn’t Killing You. Medium (blog).
- N10 · r79b · Observational study – Wikipedia
- N11 · v09h · Nitrite – Wikipedia
- N12 · esug · Hème – Wikipedia
- N13 · 7ko9 · Nitrosamine – Wikipedia
- N14 · awtr · The Truth About Nitrite in Lunch Meat
- N15 · 5v9s · Bacon Causes Cancer ? Sort of. Not Really. Ish.
- N16 · fq5n · Le cancer n’est-il vraiment que le fruit de mutations génétiques ?
- N17 · n3j6 · Otto Heinrich Warburg – Wikipedia
- N18 · mo8r · Warburg effect – Wikipedia
- N19 · alc0 · Mitochondrie – Wikipedia
- N20 · g2gs · Organite – Wikipedia
- N21 · 7gdc · Cytoplasme – Wikipedia
- N22 · kmst · Mitochondrial Fuel – Which Fuel You Burn In Your Mitochondria for Energy Determines How Long Your Mitochondria Last and That Determines How Long You Live !
- N23 · e3yx · Apoptose – Wikipedia
- N24 · 0ubw · Métastase – Wikipedia
- N25 · dld1 · Glycolyse – Wikipedia
- N26 · qqzu · Acide lactique – Wikipedia
- N27 · e87p · Acide pyruvique – Wikipedia
- N28 · 5osv · Cycle de Krebs – Wikipedia
- N29 · pl29 · Cordier-Bussat, M. et al. (2018). Même l’effet Warburg est oxydable : Coopération métabolique et développement tumoral. Med Sci (Paris), 34, 8–9, août–septembre.
- N30 · 12ty · Oncogène – Wikipedia
- N31 · 16ls · Warburg hypothesis – Wikipedia
- N32 · a0hn · Émission France Culture “Mitochondrie, de l’énergie plein la cellule”
- N33 · 57ji · Oncogenèse
- N34 · jovq · Dysregulated metabolism contributes to oncogenesis
- N35 · f0fq · Métabolisme – Wikipedia
- N36 · rcy1 · Enzyme – Wikipedia
- N37 · gwl3 · Cytosol – Wikipedia
- N38 · 9rri · Épiphénomène – Wikipedia
- N39 · 2d27 · Épigénétique – Wikipedia
- N40 · 36mo · Virus oncogène – Wikipedia
- N41 · newj · Acide ribonucléique – Wikipedia
- N42 · x2ad · Transcriptase inverse – Wikipedia
- N43 · uhl6 · The Nobel Prize in Physiology or Medicine 1989 – J. Michael Bishop, Harold E. Varmus
- N44 · 2ggw · Gène suppresseur de tumeurs – Wikipedia
- N45 · ucte · Schwartz, L (2019). La fin des maladies ? Une approche révolutionnaire de la médecine. Les Liens qui Libèrent.
- N46 · l23i · Djikeussi, E (2022). Cancer : Maladie génétique ou crise énergétique cellulaire ? Le pouvoir de l’alimentation. Gap : Le Souffle d’Or.
- N47 · p4mf · Projet Génome humain – Wikipedia
- N48 · lr2n · Agent alkylant – Wikipedia
- N49 · 4b6z · Variation in cancer risk among tissues can be explained by the number of stem cell divisions
- N50 · od79 · Cellule souche – Wikipedia
- N51 · t350 · Bad Luck of Random Mutations Plays Predominant Role in Cancer, Study Shows
- N52 · w9oi · Non, le cancer n’est pas le fruit du hasard !
- N53 · 4wjx · Cancer – Wikipedia
- N54 · 8dug · Gorski, D (2011). Why haven’t we cured cancer yet ? Science-based medicine.
- N55 · 8duy · The cancer screening kerfuffle erupts again : “Rethinking” screening for breast and prostate cancer
- N56 · rt4q · Discovery of Ancient Cancer in 1.7 Million-Year-Old Fossil
- N57 · 1wwb · Séquençage – Wikipedia
- N58 · b6a0 · The Cancer Genome Atlas – Wikipedia
- N59 · k2cw · The Cancer Genome Atlas : More Than a Large Collection of Data
- N60 · dqek · The Cancer Genome Atlas : funding – Wikipedia
- N61 · 3g3i · Agus, David (2009). A new strategy in the war on cancer. TEDmed video (sous-titrée en 20 langues).
- N62 · 3te7 · Crunch data to live longer, says David Agus – the doctor who treats the stars
- N63 · 9wzv · Hillis, Danny (2010). Understanding cancer through proteomics. TEDmed video.
- N64 · 61bq · Protéomique – Wikipedia
- N65 · x10x · Protéome – Wikipedia
- N66 · sovd · Électrophorèse bidimensionnelle – Wikipedia
- N67 · li6h · Kinome – Wikipedia
- N68 · se0a · Acide zolédronique – Wikipedia
- N69 · antl · Mass spectrometry for translational proteomics : progress and clinical implications
- N70 · exn1 · Génomique – Wikipedia
- N71 · w53x · Big data – Wikipedia
- N72 · fufq · Cytokine – Wikipedia
- N73 · 1h7l · Maryáš, J et al. (2014). Proteomics in investigation of cancer metastasis : functional and clinical consequences and methodological challenges. Proteomics. 2014, 14, 4–5 : 426–40.
- N74 · r0v5 · Interactome – Wikipedia
- N75 · fkew · Matière noire – Wikipedia
- N76 · 4og3 · Tomasetti, Cristian et al. (2015). Only three driver gene mutations are required for the development of lung and colorectal cancers. Proc Natl Acad Sci U S A. 2015, 112, 1 : 118–123.
- N77 · c2nc · L’épigénétique, l’hérédité au-delà de l’ADN
Article créé le 22/02/2016 - modifié le 19/10/2024 à 18h10 • 8 445 visites



{kind=link}